Setting Up AWS Lambda Function
Introduction
AWS Lambda is a serverless compute service that lets you run code without provisioning or managing servers. In this guide, we’ll walk through the steps to set up an AWS Lambda function to process our data.
Step-by-Step Guide to Create an AWS Lambda Function
Access the AWS Lambda Console: Navigate to the AWS Lambda dashboard.
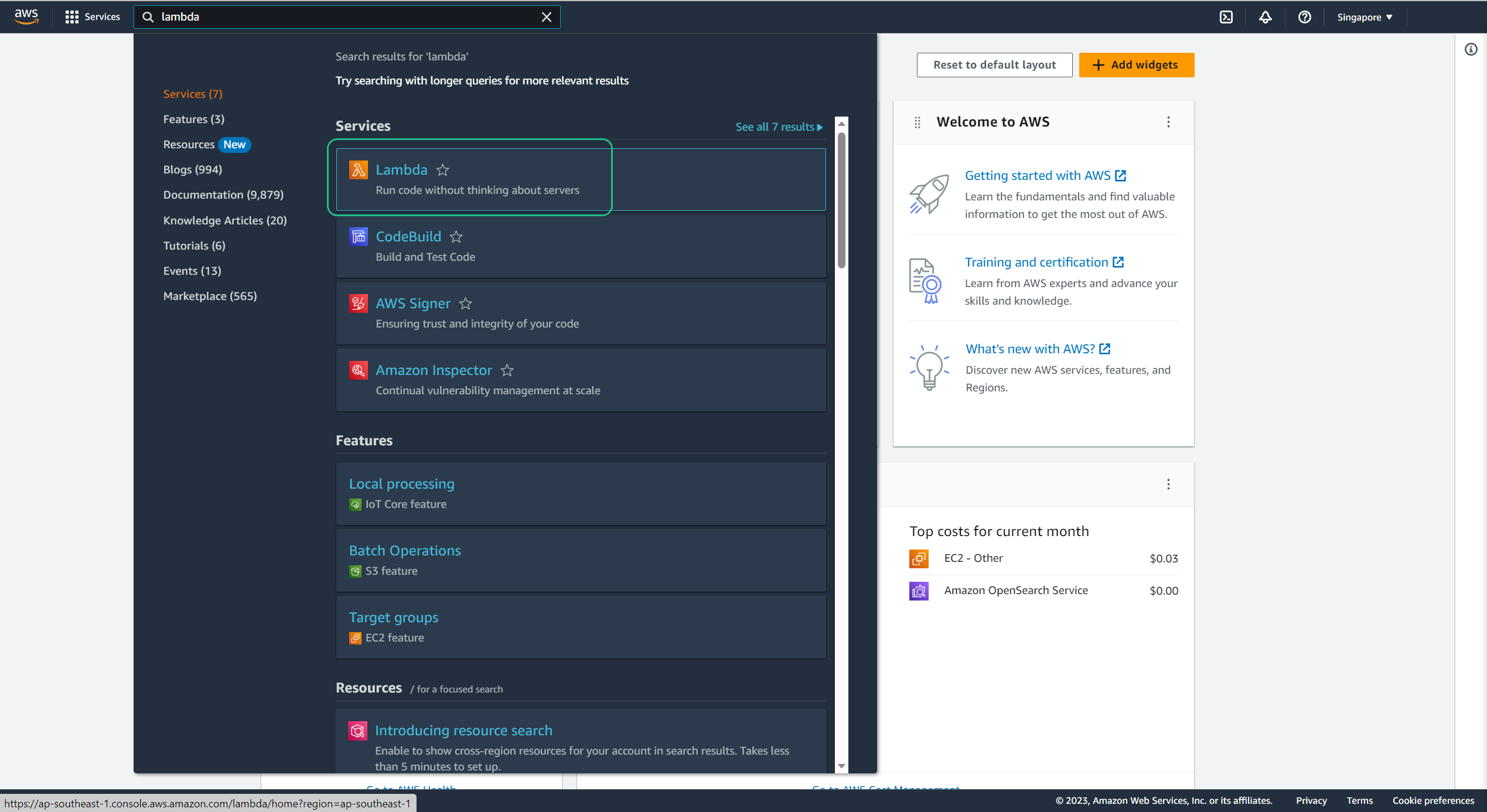
Initiate Function Creation: Click on Create function.
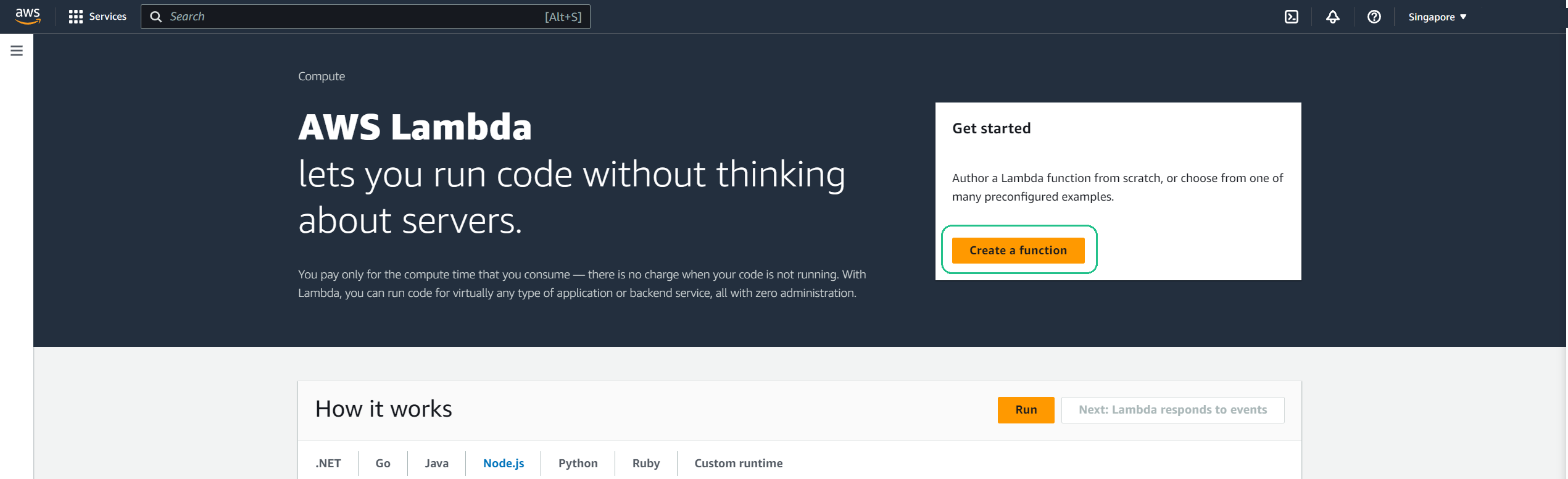
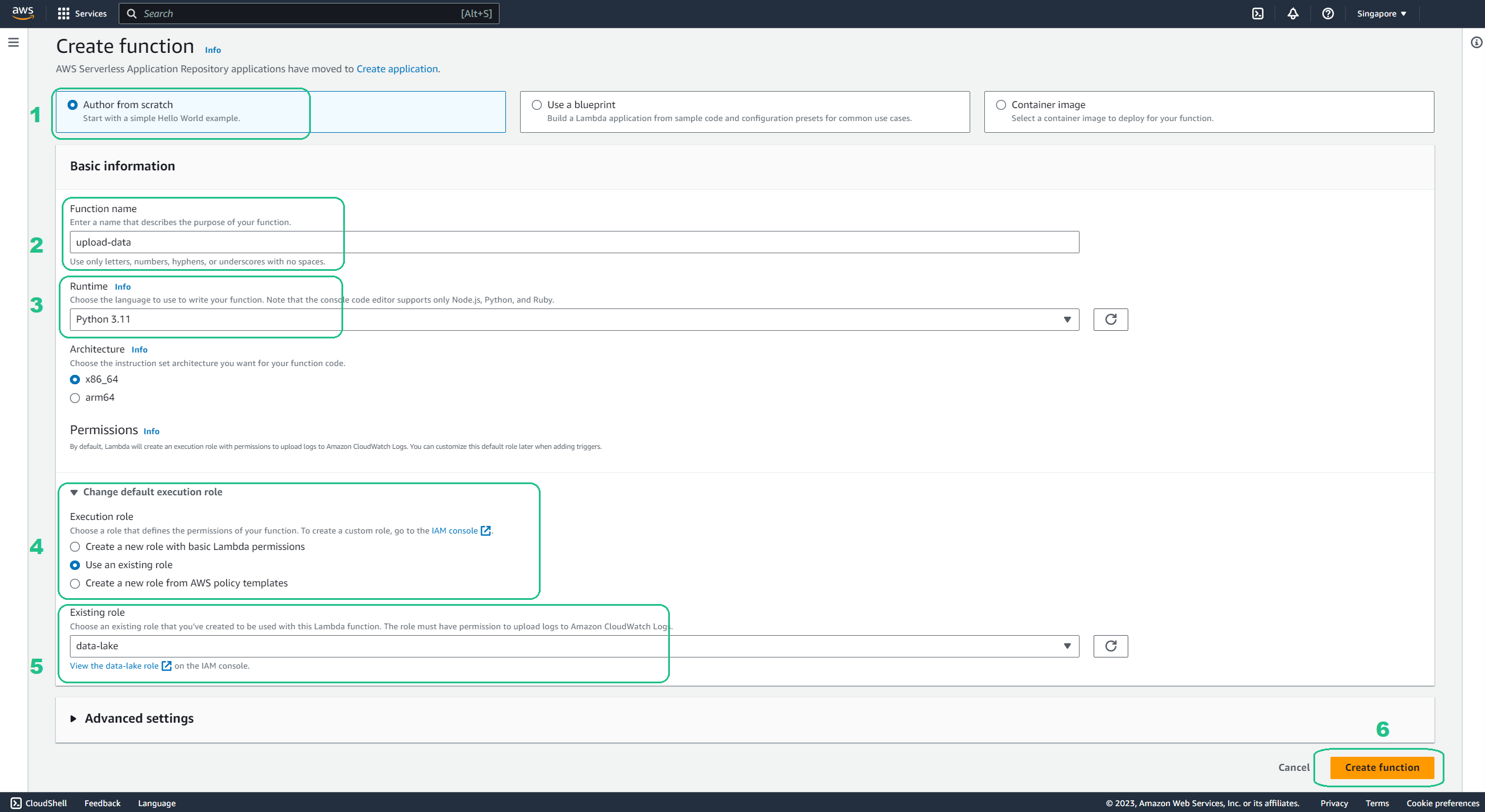
Function Configuration:
- Author from scratch: Keep this option selected
- Name: Provide a name for your Lambda function (e.g.,
upload-data). - Runtime: Select the latest supported version of Python
- Permissions: Expand Change default execution role
- Execution role: Use an existing role
- Existing role: data-lake
Set up Lambda:
Upload code: If you have a
.zipfile (like theupload-data.zip), choose “Upload a .zip file” and upload your file.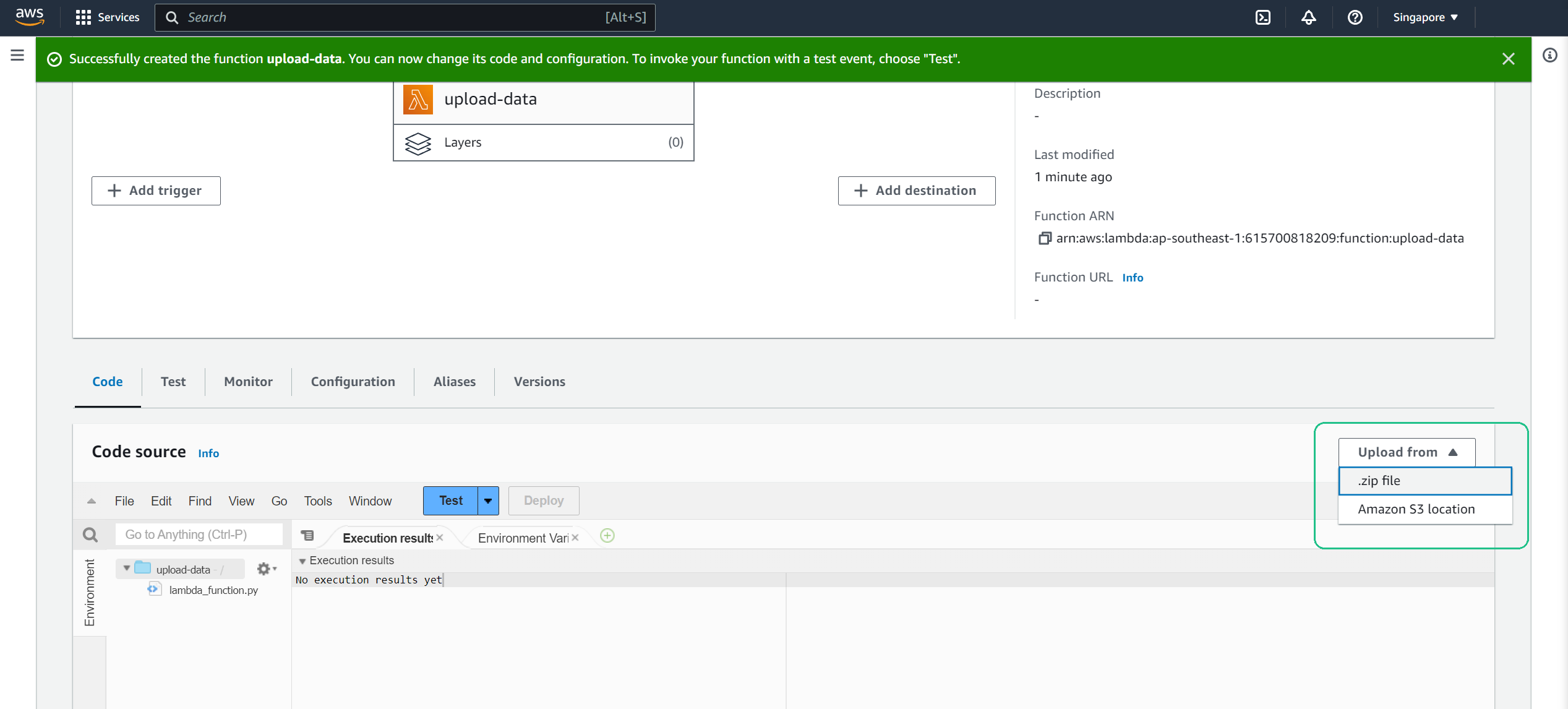
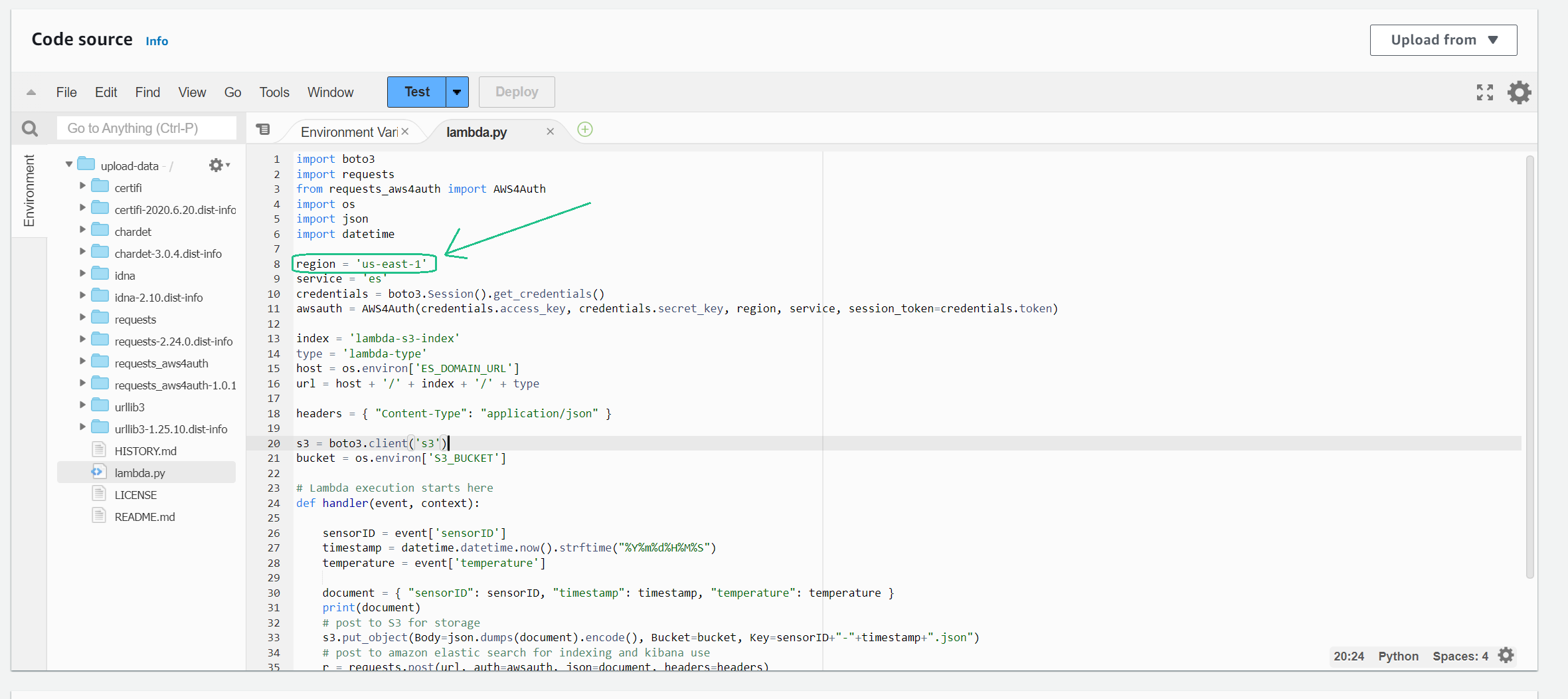
Set region: Set value of region to your current region you practice the lab (e.g. ap-southeast-1)
Runtime settings: Scroll to Runtime settings and choose Edit then

In the Handler box, replace the existing value with
lambda.handlerand choose Save.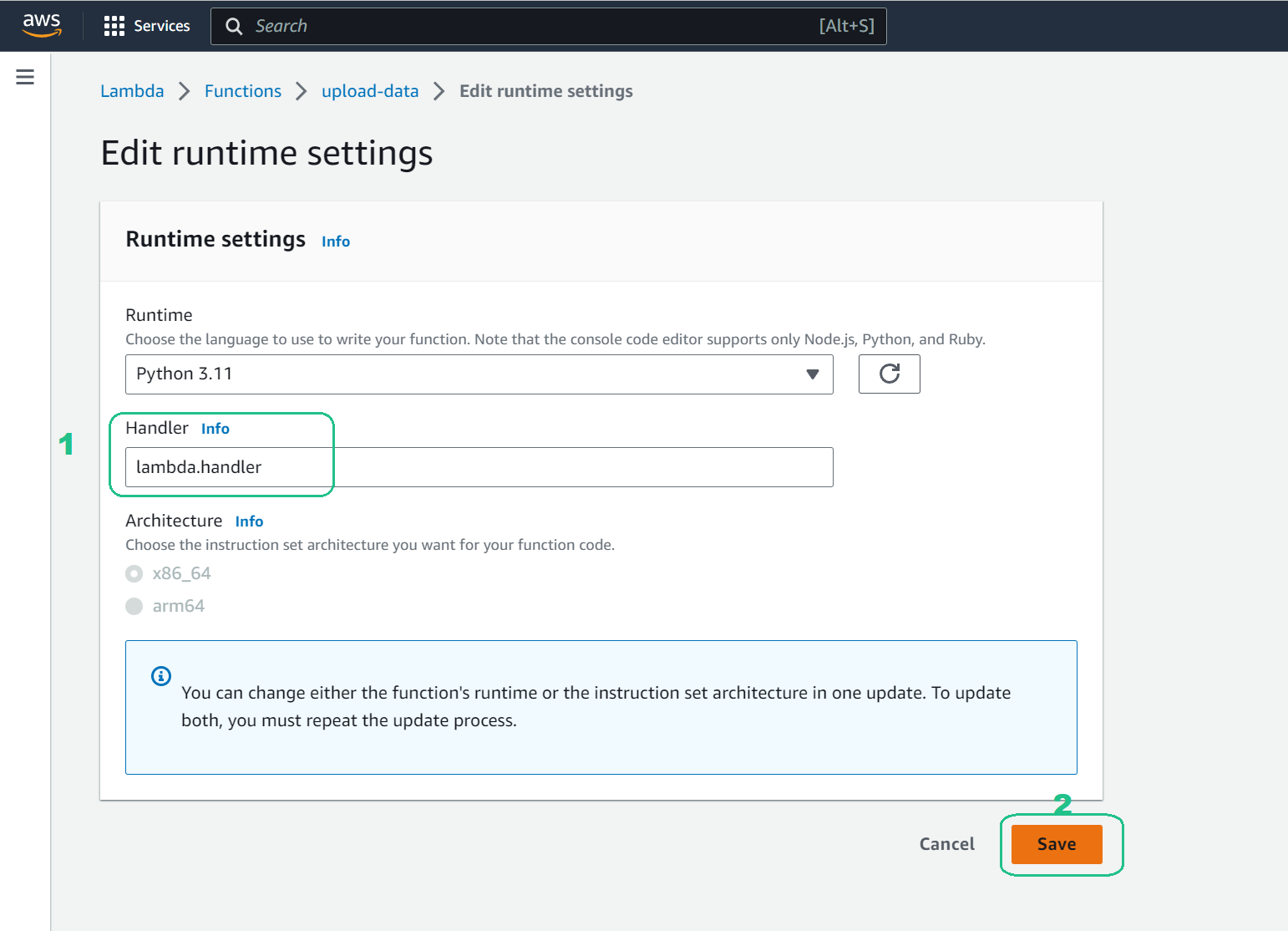
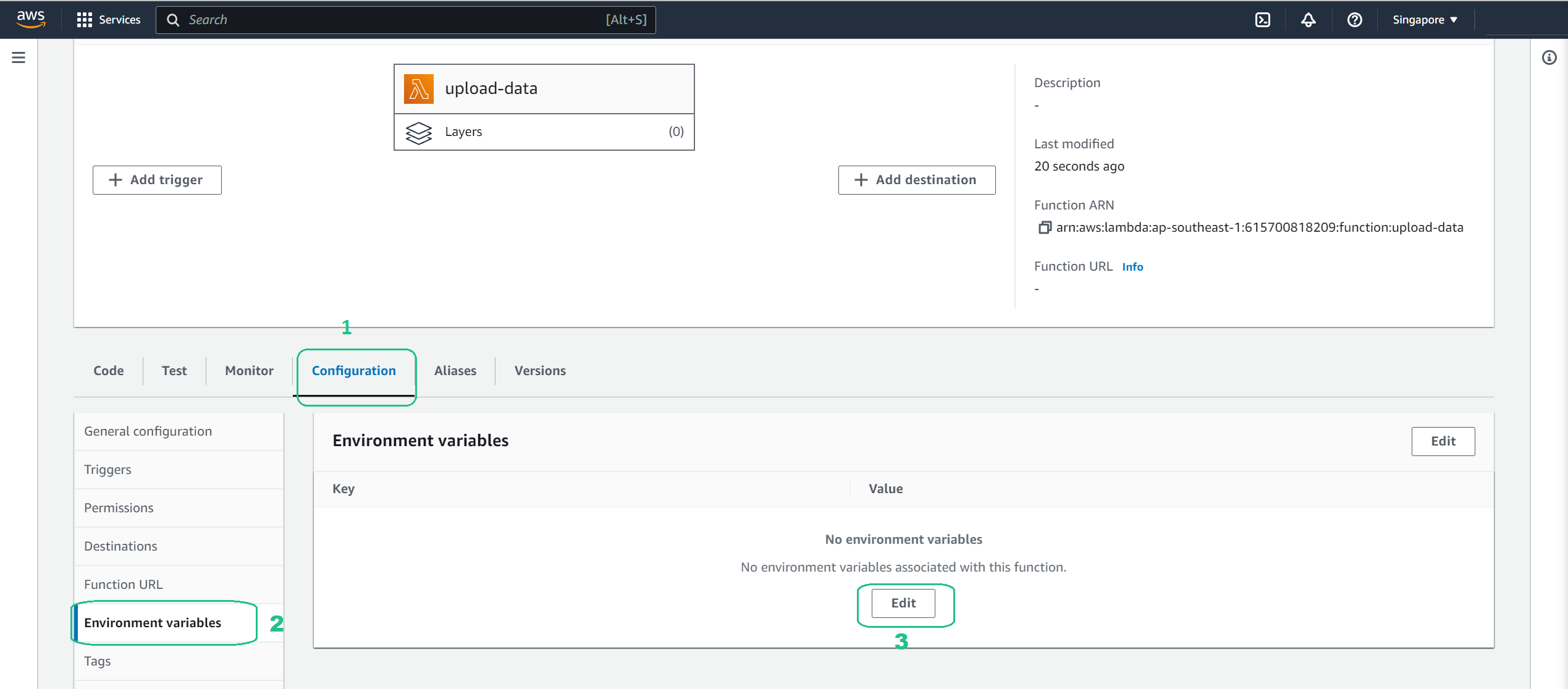
Environment Variables: Choose the Configuration tab, choose Environment variables and then choose Edit.
Choose Add environment variable and configure the following settings. Key:
S3_BUCKETValue: Paste your bucket name (e.g.,datalakes-workshop1)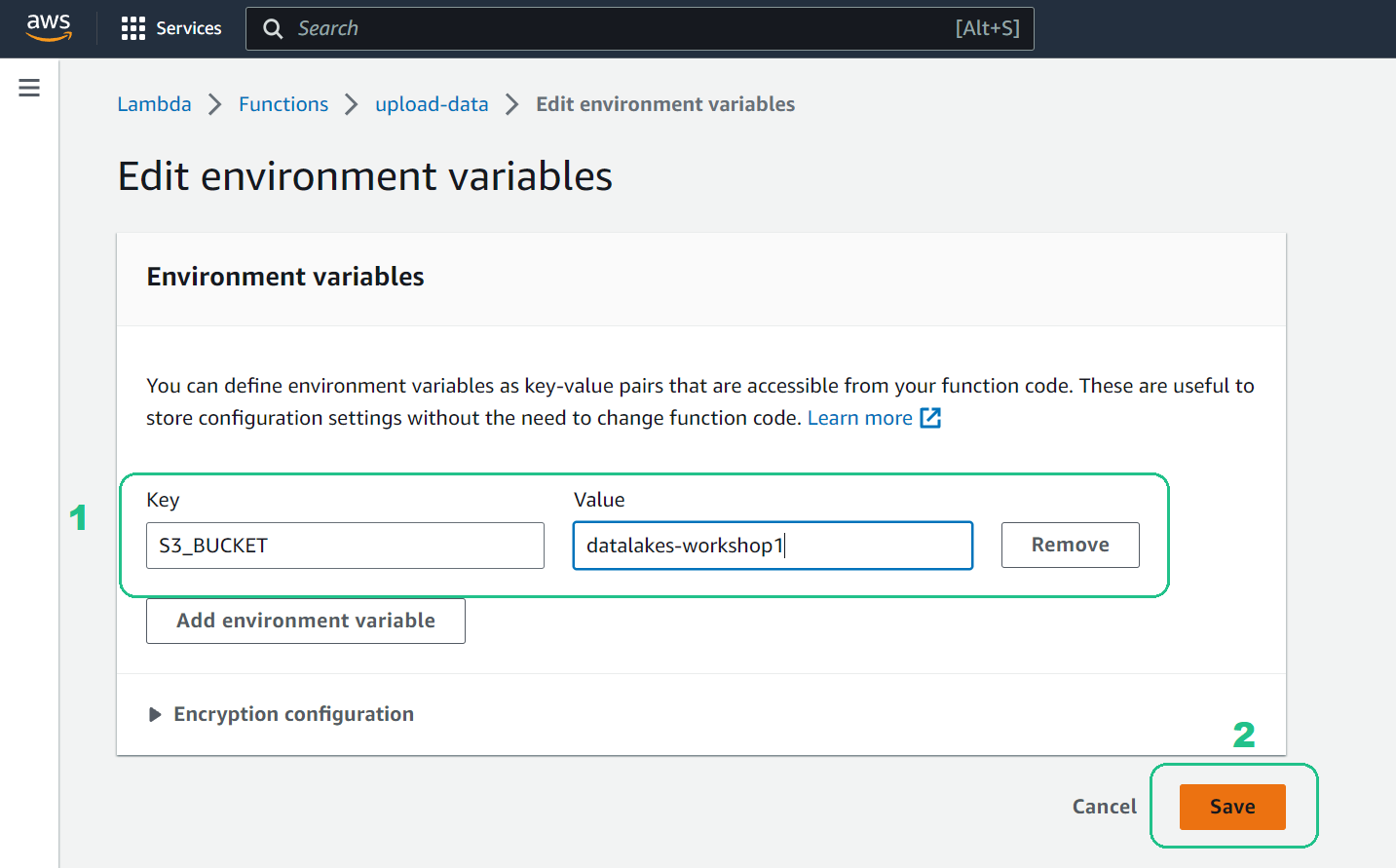
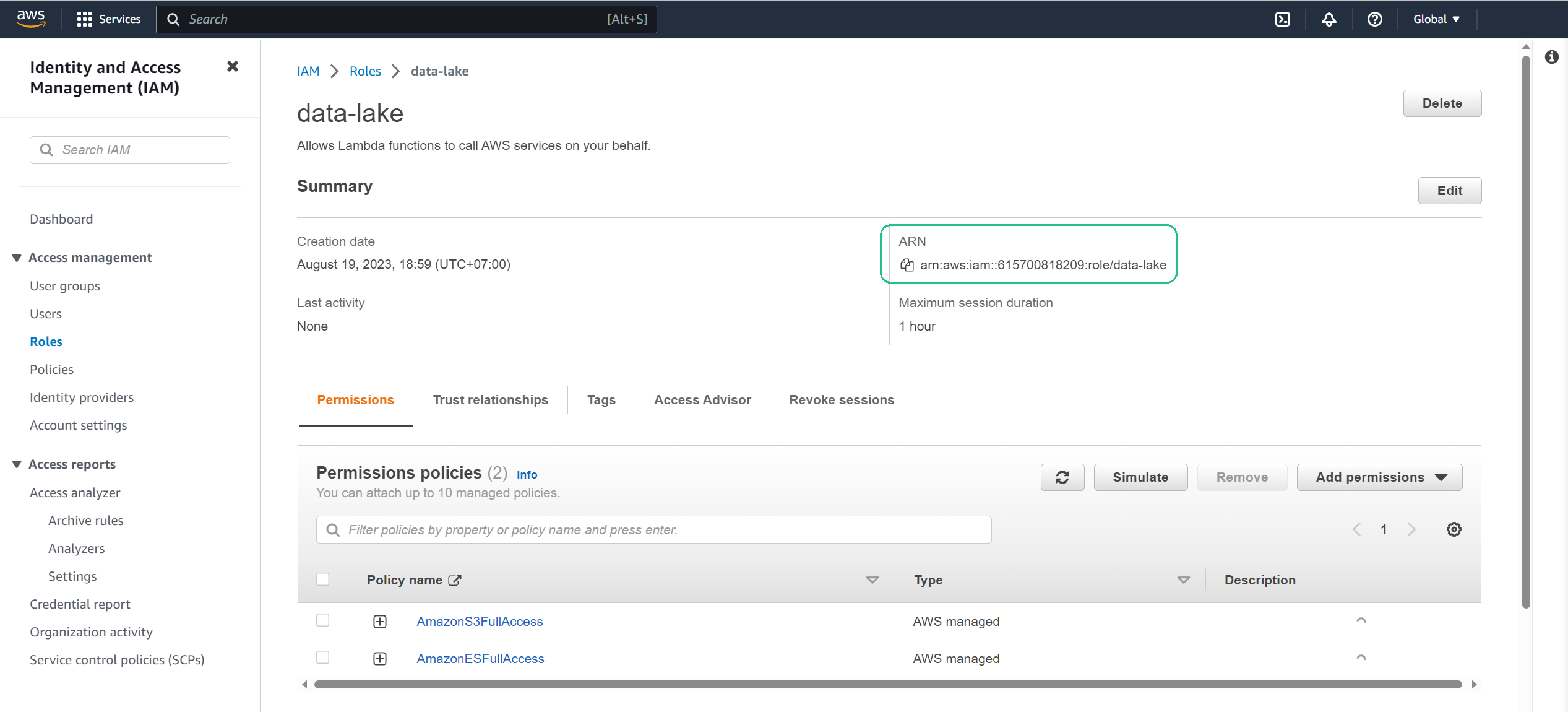
Amazon Resource Name: In the Configuration tab menu, choose Permissions. Under Role name, choose the data-lake link.
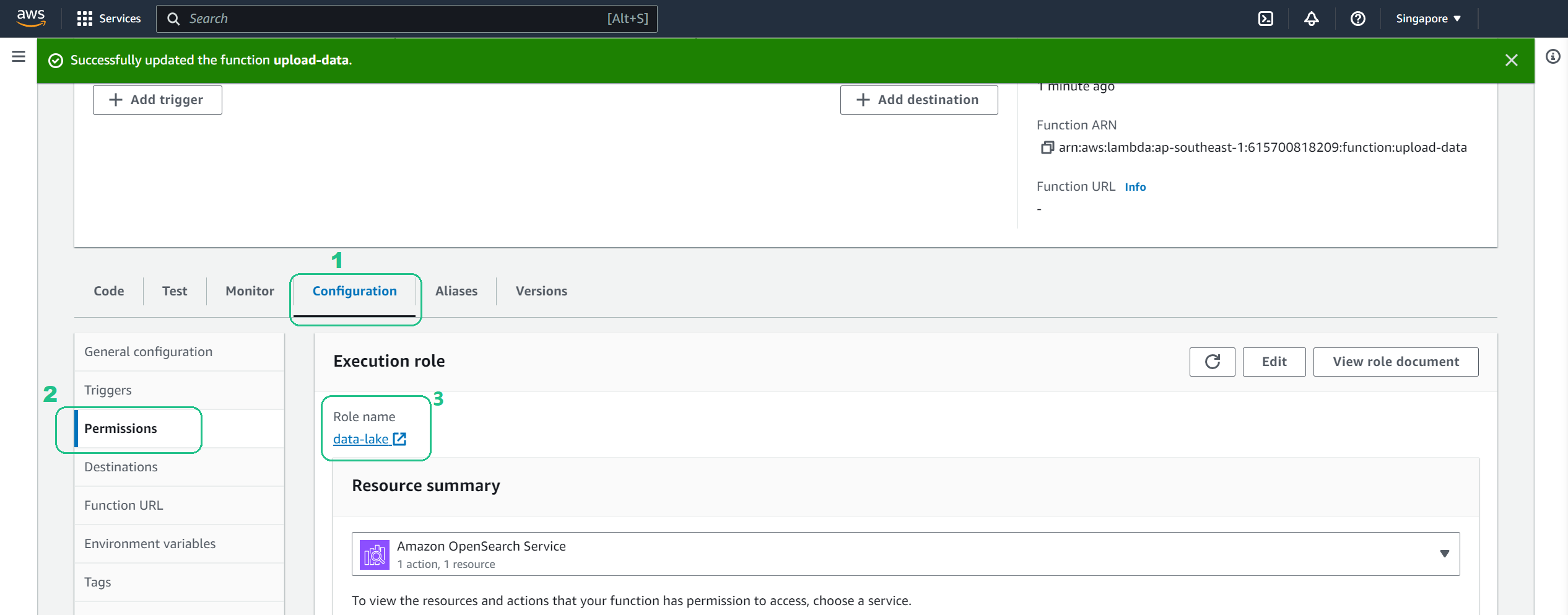
Copy the role Amazon Resource Name (ARN), we’ll use it in future sections.
Conclusion
With the AWS Lambda function now set up, you’re equipped to process and ingest data into your data lake. In the upcoming sections, we’ll delve into integrating this function with our Amazon S3 bucket and Amazon OpenSearch Service.